04 bước chi tiết để phân tích dữ liệu văn bản
Trong bài viết này chúng ta sẽ tìm hiểu các kỹ thuật phân tích dữ liệu được ứng dụng cụ thể như thế nào trong từng bước thực hiện. Hãy cùng tìm hiểu ngay.
Nhờ vào sức mạnh của AI, phân tích dữ liệu văn bản có thể áp dụng trên nhiều loại văn bản khác nhau, tùy thuộc vào yêu cầu đầu ra của bài toán, ví dụ:
- Toàn bộ tài liệu: thu thập thông tin từ một tài liệu hoặc đoạn văn hoàn chỉnh. Ví dụ: cảm nhận tổng thể về đánh giá của khách hàng.
- Các câu đơn: thu thập thông tin từ các câu cụ thể. Ví dụ: cảm nhận chi tiết hơn trong từng câu đánh giá của khách hàng.
- Các vế câu: thu thập thông tin từ các vế trong một câu.
Một khi đã biết cách chia nhỏ dữ liệu, bạn có thể bắt đầu việc phân tích văn bản với các bước lần lượt sau đây.
Thu thập dữ liệu
Bạn có thể thu thập dữ liệu về thương hiệu, sản phẩm hoặc dịch vụ từ cả nguồn nội bộ và bên ngoài doanh nghiệp.
Dữ liệu nội bộ
Đây là dữ liệu bạn tạo ra hàng ngày, từ email, cuộc trò chuyện, đến khảo sát, truy vấn của khách hàng và phiếu hỗ trợ khách hàng.
Bạn chỉ cần truy xuất dữ liệu này từ phần mềm hoặc nền tảng dưới dạng tệp CSV hoặc Excel hay kết nối API để truy xuất trực tiếp.
Một số ví dụ về dữ liệu nội bộ:
- Phần mềm dịch vụ khách hàng: phần mềm giao tiếp với khách hàng, quản lý các truy vấn của người dùng và giải quyết các vấn đề hỗ trợ khách hàng: Zendesk, Freshdesk và Help Scout là một vài ví dụ.
- CRM: phần mềm theo dõi tất cả các tương tác với khách hàng hoặc khách hàng tiềm năng. Nó có thể liên quan đến các lĩnh vực khác nhau, từ hỗ trợ khách hàng đến bán hàng và tiếp thị. Hubspot, Salesforce và Pipedrive là những ví dụ về CRM.
- Trò chuyện: các ứng dụng giao tiếp với các thành viên trong nhóm hoặc khách hàng, như Slack, Hipchat, Intercom và Drift.
- Email: email vẫn là công cụ phổ biến nhất để quản lý các cuộc trò chuyện với khách hàng và các thành viên trong nhóm.
- Khảo sát: thường được sử dụng để thu thập phản hồi về dịch vụ khách hàng, phản hồi về sản phẩm hoặc để thực hiện nghiên cứu thị trường, như Typeform, Google Forms và SurveyMonkey.
- NPS (Net Promoter Score): một trong những thước đo phổ biến nhất cho trải nghiệm khách hàng trên thế giới. Nhiều công ty sử dụng phần mềm theo dõi NPS để thu thập và phân tích phản hồi từ khách hàng của họ. Một vài ví dụ là Delighted, Promoter.io và Satismeter.
- Cơ sở dữ liệu: cơ sở dữ liệu là một tập hợp thông tin. Bằng cách sử dụng hệ thống quản lý cơ sở dữ liệu, một công ty có thể lưu trữ, quản lý và phân tích tất cả các loại dữ liệu. Ví dụ về cơ sở dữ liệu bao gồm Postgres, MongoDB và MySQL.
- Phân tích sản phẩm: phản hồi và thông tin về tương tác của khách hàng với sản phẩm hoặc dịch vụ. ProductBoard và UserVoice là hai công cụ bạn có thể sử dụng để xử lý phân tích sản phẩm.
Dữ liệu bên ngoài
Đây là dữ liệu văn bản về thương hiệu hoặc sản phẩm xuất hiện khắp nơi trên internet. Bạn có thể sử dụng các công cụ rà soát web, API và bộ dữ liệu mở để thu thập dữ liệu bên ngoài từ mạng xã hội, trang báo, tin tức, đánh giá trực tuyến, diễn đàn, v.v. và phân tích dữ liệu đó bằng các mô hình học máy.
- Công cụ khai thác dữ liệu web
- Công cụ khai thác dữ liệu web trực quan (Visual Web Scraping Tools): bạn có thể tạo công cụ khai thác dữ liệu web của riêng mình, với sự trợ giúp của Dexi.io, Portia và ParseHub.e.
- Framework khai thác dữ liệu web (Web Scraping Frameworks): các lập trình viên dày dạn kinh nghiệm có thể hưởng lợi từ các công cụ, như Scrapy trong Python và Wombat trong Ruby, để tạo các bộ dữ liệu tùy chỉnh.
- API
Ví dụ: Facebook, Twitter và Instagram có API của riêng họ và cho phép bạn trích xuất dữ liệu từ nền tảng của họ. Các phương tiện truyền thông lớn như New York Times hoặc The Guardian cũng có API riêng và bạn có thể sử dụng chúng để tìm kiếm kho lưu trữ hoặc thu thập nhận xét của người dùng.
- Tích hợp
Các công cụ SaaS (phần mềm dạng dịch vụ – Software-as-a-Service) cung cấp tích hợp với các công cụ bạn đã sử dụng. Bạn có thể kết nối trực tiếp với Twitter, Google Trang tính, Gmail, Zendesk, SurveyMonkey, Rapidminer, v.v. và thực hiện phân tích văn bản trên dữ liệu Excel bằng cách tải lên một tệp.
Chuẩn bị dữ liệu
Hầu hết quy trình này sẽ diễn ra tự động. Tuy nhiên, điều quan trọng là phải hiểu rằng phân tích văn bản tự động sử dụng một số kỹ thuật xử lý ngôn ngữ tự nhiên (NLP) như dưới đây
Mã hóa, Gắn thẻ từng phần và Phân tích cú pháp
Tokenization là quá trình chia nhỏ một chuỗi ký tự thành các phần có ý nghĩa ngữ nghĩa và có thể phân tích được (ví dụ: từ), đồng thời loại bỏ các phần vô nghĩa (ví dụ: khoảng trắng).
Các ví dụ dưới đây cho thấy hai cách khác nhau để mã hóa chuỗi ‘Analyzing text is not that hard’
(Sai) Analyzing text is not that hard. = [“Analyz”, “ing text”, “is n”, “ot that”, “hard.”]
(Đúng) Analyzing text is not that hard. = [“Analyzing”, “text”, “is”, “not”, “that”, “hard”, “.”]
Sau khi mã hóa, các mã (tokens) trải qua bước phân loại. Gắn thẻ từng phần đề cập đến quá trình gán một danh mục ngữ pháp, chẳng hạn như danh từ, động từ, v.v. cho các tokens.
Dưới đây là các thẻ PoS của các tokens từ câu trên:
“Analyzing”: động từ, “text”: danh từ, “is”: động từ, “not”: trạng từ, “that”: trạng từ, “hard”: tính từ, “.”: dấu chấm câu.
Với tất cả các tokens được phân loại và một mô hình ngôn ngữ (tức là ngữ pháp), hệ thống hiện có thể tạo ra các biểu diễn phức tạp hơn của các văn bản mà nó sẽ phân tích. Quá trình này được gọi là phân tích cú pháp. Nói cách khác, phân tích cú pháp đề cập đến quá trình xác định cấu trúc cú pháp của một văn bản. Để thực hiện điều này, thuật toán phân tích cú pháp sử dụng ngữ pháp của ngôn ngữ mà văn bản đã được viết. Các biểu diễn khác nhau sẽ là kết quả của việc phân tích cú pháp của cùng một văn bản với các ngữ pháp khác nhau.
Phân tích cú pháp phụ thuộc
Ngữ pháp phụ thuộc có thể được định nghĩa là những ngữ pháp thiết lập quan hệ chỉ đạo giữa các từ của câu. Phân tích cú pháp phụ thuộc là quá trình sử dụng ngữ pháp phụ thuộc để xác định cấu trúc cú pháp của một câu:

Phân tích cú pháp theo cấu trúc
Phương pháp này dựa trên tính hình thức của các ngữ pháp không có ngữ cảnh. Trong loại này, câu được chia thành các thành phần, nghĩa là các cụm từ phụ thuộc về một loại cụ thể trong ngữ pháp. Phân tích cú pháp đề cập đến quá trình sử dụng ngữ pháp thành phần để xác định cấu trúc cú pháp của một câu:
Cấu trúc cung cấp đặc điểm kỹ thuật về cách xây dựng câu hợp lệ, sử dụng một bộ quy tắc. Ví dụ, quy tắc VP -> VNP có nghĩa là chúng ta có thể tạo một cụm động từ (VP) bằng cách sử dụng một động từ (V) và sau đó là một cụm danh từ (NP).

Có thể thấy trong các hình trên, đầu ra của các thuật toán phân tích cú pháp chứa rất nhiều thông tin có thể giúp bạn hiểu độ phức tạp về cú pháp (và một số ngữ nghĩa) của văn bản định phân tích.
Tùy thuộc vào từng bài toán, bạn có thể áp dụng các chiến lược và kỹ thuật phân tích cú pháp khác nhau. Tuy nhiên, hiện tại, phân tích cú pháp phụ thuộc dường như hoạt động tốt hơn các cách tiếp cận khác.
Bổ ngữ (Lemmatization) và tạo gốc (Stemming)
Từ gốc và bổ đề đều đề cập đến quá trình loại bỏ tất cả các phụ tố (tức là hậu tố, tiền tố, v.v.) được gắn vào một từ để giữ cơ sở từ vựng của nó, còn được gọi là gốc. Sự khác biệt chính giữa hai quy trình này là việc tạo gốc (stemming) thường dựa trên các quy tắc cắt bớt phần đầu và phần cuối của từ, trong khi việc bổ ngữ hóa (Lemmatization) sử dụng từ điển và phân tích hình thái phức tạp hơn nhiều.
Loại bỏ từ vô nghĩa
Để phân tích tự động văn bản chính xác hơn, chúng ta cần loại bỏ các từ cung cấp rất ít thông tin ngữ nghĩa hoặc không có nghĩa gì cả. Những từ này còn được gọi là từ dừng: a, and, or, the, etc.
Có nhiều danh sách từ dừng khác nhau cho mọi ngôn ngữ. Tuy nhiên, điều quan trọng cần hiểu là bạn có thể cần thêm từ vào hoặc xóa từ khỏi danh sách đó tùy thuộc vào văn bản bạn muốn phân tích và phân tích bạn muốn thực hiện.
Phân tích dữ liệu văn bản
Việc phân tích văn bản phi cấu trúc không đơn giản. Có vô số phương pháp phân tích văn bản, nhưng hai trong số các kỹ thuật chính là phân loại văn bản và trích xuất văn bản.
Phân loại văn bản
Phân loại văn bản đề cập đến quá trình gán thẻ cho văn bản dựa trên nội dung của nó.
Trước đây, việc phân loại văn bản được thực hiện thủ công, tốn nhiều thời gian, không hiệu quả và không chính xác. Hiện nay các mô hình phân tích văn bản bằng học máy tự động thường hoạt động chỉ trong vài giây với độ chính xác vượt trội.
Các nhiệm vụ phân loại văn bản phổ biến nhất bao gồm phân tích cảm xúc, phát hiện chủ đề và phát hiện ý định.
Hệ thống dựa trên luật
Trong phân loại văn bản, quy tắc về cơ bản là sự liên kết do con người tạo ra giữa một mẫu ngôn ngữ có thể được tìm thấy trong văn bản và thẻ. Các quy tắc thường bao gồm các tham chiếu về các mẫu hình thái, từ vựng hoặc cú pháp, nhưng chúng cũng có thể chứa các tham chiếu về các thành phần khác của ngôn ngữ, chẳng hạn như ngữ nghĩa hoặc âm vị học.
Ưu điểm rõ ràng nhất của các hệ thống dựa trên quy tắc là chúng dễ hiểu. Tuy nhiên, việc tạo ra các hệ thống dựa trên quy tắc phức tạp cần rất nhiều thời gian và kiến thức tốt về cả ngôn ngữ học và các chủ đề được xử lý trong các văn bản mà hệ thống phải phân tích.
Trên hết, các hệ thống dựa trên quy tắc rất khó mở rộng và duy trì vì việc thêm các quy tắc mới hoặc sửa đổi các quy tắc hiện có đòi hỏi nhiều phân tích và thử nghiệm về tác động của những thay đổi này đối với kết quả dự đoán.
Hệ thống dựa trên học máy
Các hệ thống dựa trên học máy có thể đưa ra dự đoán dựa trên những gì chúng học được từ những quan sát trong quá khứ. Các hệ thống này cần được cung cấp nhiều ví dụ về văn bản và các gợi ý dự đoán (thẻ) cho mỗi ví dụ. Đây được gọi là dữ liệu đào tạo. Dữ liệu đào tạo của bạn càng nhất quán và chính xác, thì các dự đoán cuối cùng sẽ tốt hơn.
Khi bạn đào tạo một bộ phân loại dựa trên máy học, dữ liệu đào tạo phải được chuyển đổi thành vectơ (tức là danh sách các số mã hóa thông tin). Bằng cách sử dụng vectơ, hệ thống có thể trích xuất các đặc điểm có liên quan (các mẩu thông tin), giúp nó học hỏi từ dữ liệu hiện có và đưa ra dự đoán về các văn bản sắp tới.
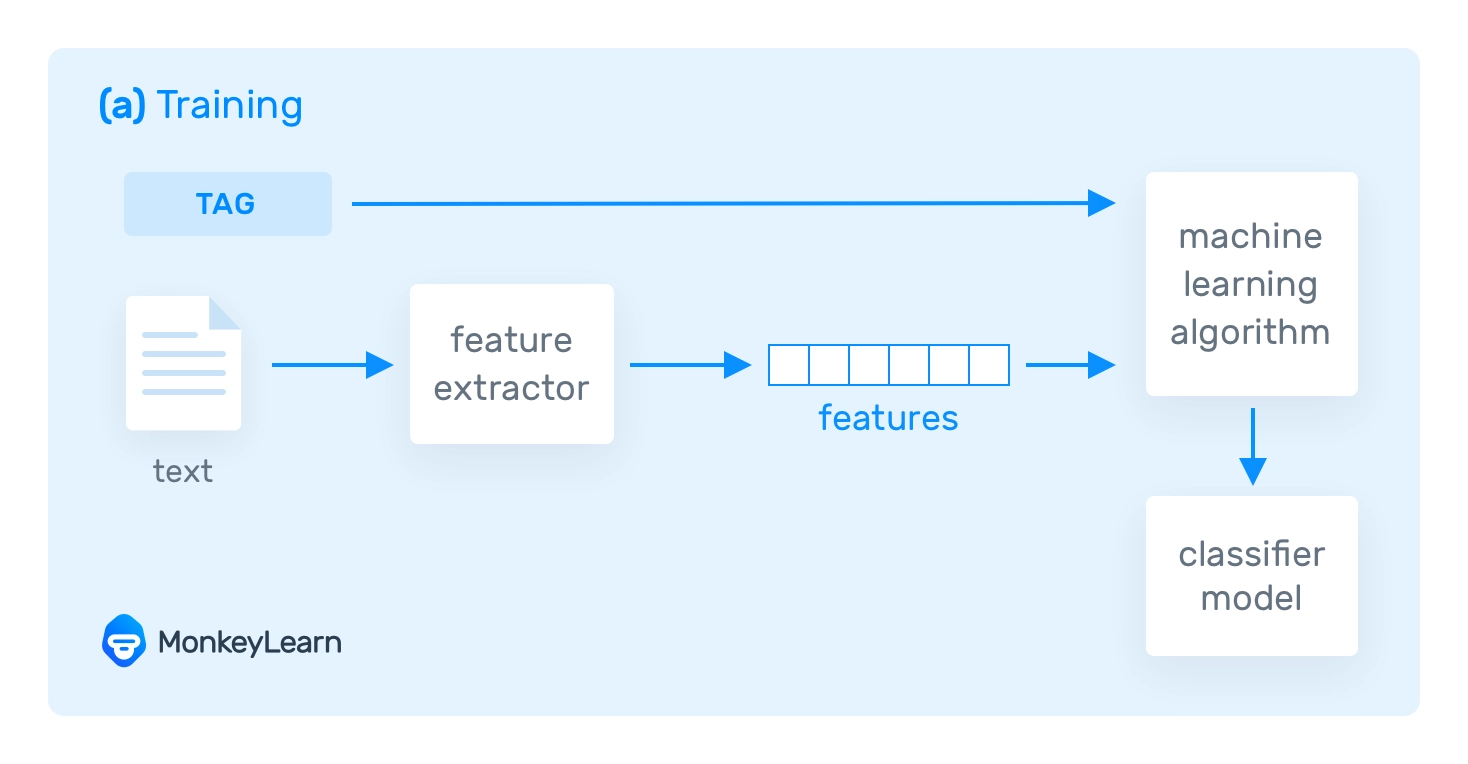
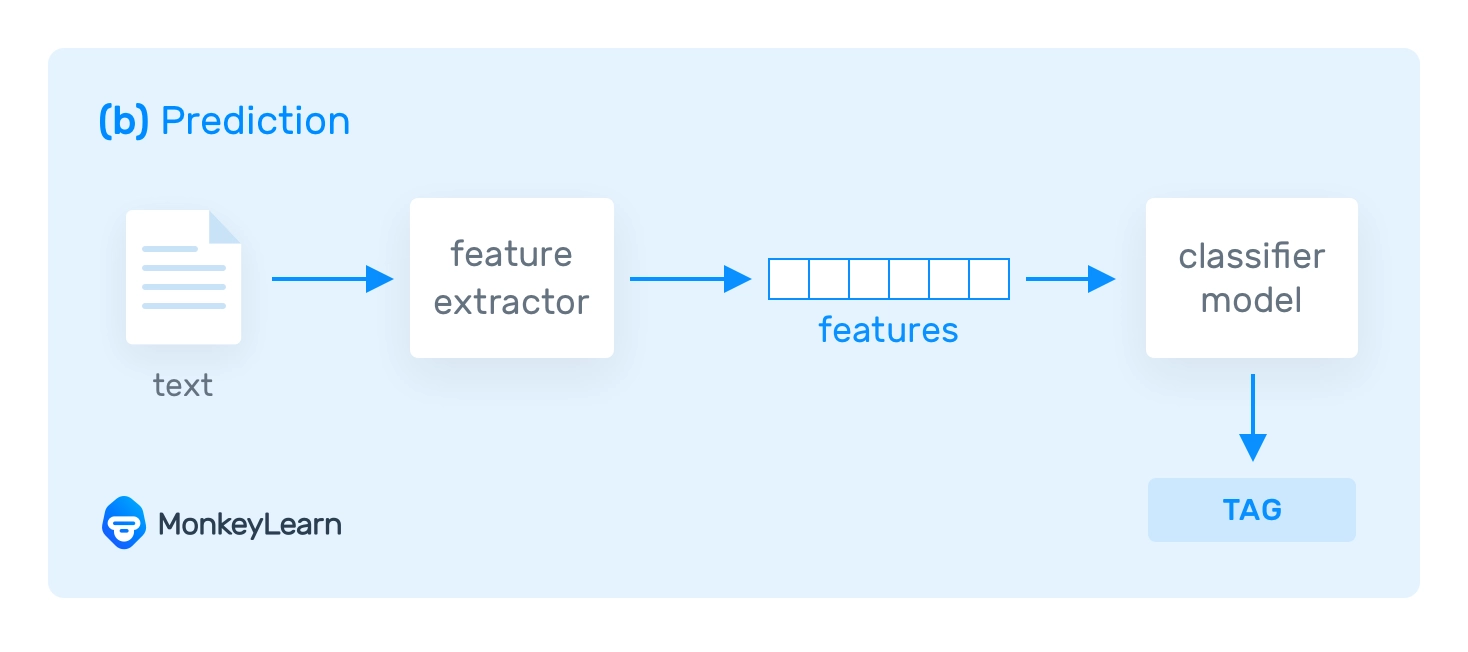
Thuật toán học máy
Có rất nhiều thuật toán học máy được sử dụng trong phân loại văn bản. Thường được sử dụng nhất là họ thuật toán Naive Bayes (NB), Support Vector Machines (SVM) và thuật toán học sâu.
Họ thuật toán Naive Bayes dựa trên Định lý Bayes. Vectơ đại diện cho văn bản mã hóa thông tin về khả năng các từ xuất hiện trong văn bản của một thẻ nhất định. Với thông tin này, xác suất của một văn bản thuộc bất kỳ thẻ nào trong mô hình có thể được tính toán. Khi tất cả các xác suất đã được tính cho một văn bản đầu vào, mô hình phân loại sẽ trả về thẻ có xác suất cao nhất làm đầu ra tương ứng.
Một trong những ưu điểm chính của thuật toán này là kết quả có thể khá tốt ngay cả khi không có nhiều dữ liệu đào tạo.
Support Vector Machines (SVM) là một thuật toán có thể chia không gian vectơ của các văn bản được gắn thẻ thành hai không gian con: một không gian chứa hầu hết các vectơ thuộc một thẻ nhất định và một không gian con khác chứa hầu hết các vectơ không thuộc về thẻ đó.
Các mô hình phân loại sử dụng SVM làm cốt lõi sẽ biến đổi văn bản thành vectơ và sẽ xác định phía nào của không gian cho một thẻ nhất định mà các vectơ đó thuộc về. Ưu điểm quan trọng nhất của việc sử dụng SVM là kết quả thường tốt hơn so với kết quả thu được với Naive Bayes. Tuy nhiên, cần nhiều tài nguyên tính toán hơn cho SVM.
Học sâu là một tập hợp các thuật toán và kỹ thuật sử dụng “mạng nơ-ron nhân tạo” để xử lý dữ liệu giống như bộ não con người. Các thuật toán này sử dụng một lượng lớn dữ liệu đào tạo (hàng triệu ví dụ) để tạo ra các biểu diễn phong phú về mặt ngữ nghĩa hơn, sau đó có thể được đưa vào các mô hình dựa trên học máy để đưa ra dự đoán chính xác hơn nhiều so với các mô hình truyền thống.

Hệ thống hỗn hợp
Các hệ thống kết hợp thường chứa các hệ thống dựa trên học máy và các hệ thống dựa trên luật để cải thiện khả năng dự đoán.
Trích xuất văn bản
Trích xuất văn bản đề cập đến quá trình nhận dạng các phần thông tin có cấu trúc từ văn bản không có cấu trúc. Ví dụ: tự động phát hiện các từ khóa có liên quan nhất từ một đoạn văn bản, xác định tên của các công ty trong một bài báo, phát hiện bên cho thuê và bên thuê trong hợp đồng tài chính hoặc xác định giá trên mô tả sản phẩm.
Biểu thức chính quy
Biểu thức chính quy (còn gọi là regexes) hoạt động tương đương với các quy tắc được xác định trong nhiệm vụ phân loại. Trong trường hợp này, một biểu thức chính quy xác định một mẫu ký tự sẽ được liên kết với một thẻ.
Ví dụ: mẫu bên dưới sẽ phát hiện hầu hết các địa chỉ email trong một văn bản nếu chúng đứng trước và theo sau bởi dấu cách:
(?i)\b(?:[a-zA-Z0-9_-.]+)@(?:(?:[[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(?:(?:[a-zA-Z0-9-]+.)+))(?:[a-zA-Z]{2,4}|[0-9]{1,3})(?:]?)\b
Bằng cách phát hiện mẫu này trong văn bản và gán thẻ email cho nó, ta có thể tạo một trình trích xuất địa chỉ email đơn giản.
Về mặt tích cực, với cách tiếp cận này, bạn có thể tạo trình trích xuất văn bản một cách nhanh chóng và kết quả thu được có thể tốt, miễn là bạn có thể tìm thấy các mẫu phù hợp cho loại thông tin bạn muốn phát hiện. Mặt khác, các biểu thức chính quy có thể cực kỳ phức tạp và có thể thực sự khó khăn để duy trì và mở rộng quy mô, đặc biệt khi cần nhiều biểu thức để trích xuất các mẫu mong muốn.
Trường ngẫu nhiên có điều kiện
Trường ngẫu nhiên có điều kiện (Conditional Random Fields – CRF) là một phương pháp thống kê thường được sử dụng trong trích xuất văn bản dựa trên học máy. Cách tiếp cận này tìm hiểu các mẫu sẽ được trích xuất bằng cách cân nhắc một tập hợp các đặc điểm của chuỗi các từ xuất hiện trong một văn bản. Thông qua việc sử dụng CRF, ta có thể thêm nhiều biến phụ thuộc nhau vào các mẫu sử dụng để phát hiện thông tin trong văn bản, chẳng hạn như thông tin cú pháp hoặc ngữ nghĩa.
Điều này thường tạo ra các mẫu phức tạp và phong phú hơn nhiều so với việc sử dụng các biểu thức thông thường và có thể mã hóa nhiều thông tin hơn. Tuy nhiên, cần nhiều tài nguyên tính toán hơn để triển khai nó vì tất cả các mẫu phải được tính toán, tất cả các chuỗi được xem xét và tất cả các trọng số được gán cho các mẫu đó phải được học trước khi xác định xem một chuỗi có thuộc thẻ hay không.
Một trong những ưu điểm chính của phương pháp CRF là khả năng tổng quát hóa. Khi một trình trích xuất đã được đào tạo bằng cách sử dụng phương pháp CRF trên các văn bản của một miền cụ thể, nó sẽ có khả năng tổng quát hóa những gì đã học được sang các miền khác một cách hợp lý.
Trực quan hóa dữ liệu văn bản
Sau khi phân tích văn bản để chia nhỏ dữ liệu, bạn sẽ làm gì với kết quả? Kinh doanh thông minh (BI) và các công cụ trực quan hóa dữ liệu giúp bạn dễ dàng hiểu kết quả của mình trong các trang tổng quan nổi bật. Một số công cụ bạn có thể sử dụng là Google Data Studio, Looker, Tableau,…
Tổng hợp

Phân tích dữ liệu văn bản là gì? Hướng dẫn cho người mới bắt đầu
Để phân tích một lượng lớn dữ liệu phi cấu trúc dưới dạng văn bản (email, cuộc trò chuyện trên mạng xã hội,…) thực sự…

10 bộ dữ liệu hỏi – đáp giúp xây dựng hệ thống chatbot mạnh mẽ
Để xây dựng một chatbot thông minh và mạnh mẽ, cần cung cấp bộ dữ liệu hỏi đáp trong quá trình đào tạo mô hình.…

Cơ sở hạ tầng dữ liệu đủ mạnh: Xây dựng như thế nào?
“Dữ liệu là dầu mỏ của thế kỷ 21” hay “dữ liệu đang trở thành nguyên liệu thô mới của hoạt động kinh doanh”? Tuy…